Ai Evals How To Systematically Improve And Evaluate Ai
Hey, Gregor here 👋 This is a paid edition of the Engineering Leadership newsletter. Every week, I share 2 articles → Wednesday’s paid edition and Sunday’s free edition, with a goal to make you a great engineering leader! Consider upgrading your account for the full experience here. AI Evals: How To Systematically Improve and Evaluate AIReal-world case study on how to improve and evaluate an AI product
IntroIf you are an engineer or an engineering manager, it is highly likely that you have already come across the topic of AI Evals in your role or you will in the near future. The reason is that most of the companies these days are increasingly looking to integrate AI into their products or completely transform them into AI products. And one thing is certain, AI Evals are becoming an increasingly important topic when it comes to building AI products. Many people across the industry are mentioning AI Evals as a crucial skill for building great AI products.
To ensure that we’ll get the best insights on AI Evals, I am happy to team up with Hamel Husain, ML Engineer with 20 years of experience helping companies with AI. This is an article for paid subscribers, and here is the full index: - 1. What Are AI Evals? Introducing Hamel HusainHamel Husain is an experienced ML Engineer who has worked for companies such as GitHub, Airbnb, and Accenture, to name a few. Currently, he’s helping many people and companies to build high-quality AI products as an independent consultant.
Together with Shreya Shankar, they are teaching a popular course called AI Evals For Engineers & PMs. I’ve thoroughly checked it out and I learned a lot about what it takes to build quality AI products, and I highly recommend it. Check the course and use my code GREGOR35 for 945$ off. The next cohort starts on July 21. 1. What Are AI Evals?1.1 AI Evals == AI Evaluations
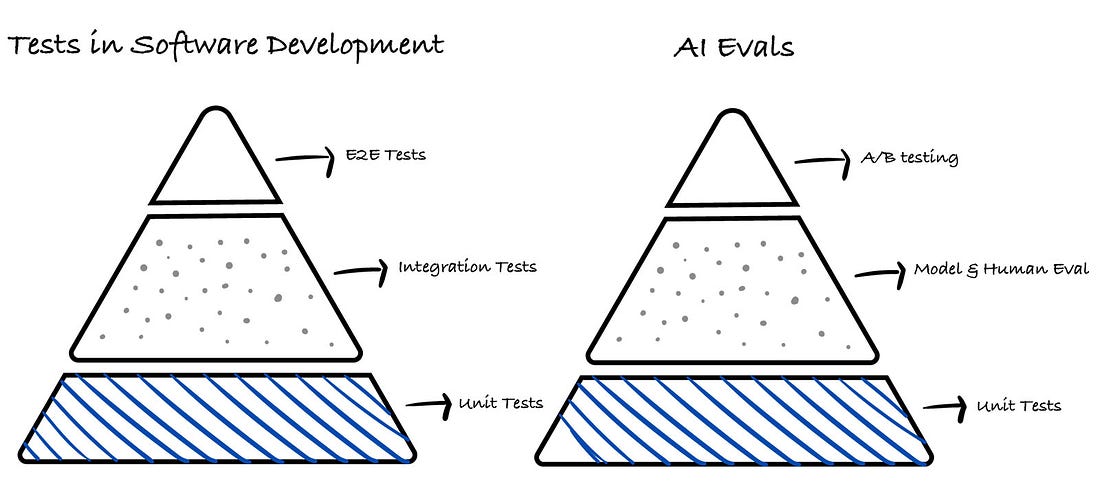
It’s a similar concept to doing Tests in Software Development, just evaluating LLMs is a lot more variable. A good evaluation produces results that can be easily and unambiguously interpreted. This usually means giving a numeric score, but it can also be a clear written summary or report with specific details. Evals (short for evaluations) can be used in different ways:
Evals are essential not only to catch errors, but also to maintain user trust, ensure safety, monitor system behavior, and enable systematic improvement. Without them, teams are left guessing where failures occur and how best to fix them. 1.2 Why Are AI Evals So Important?Think of it like this:
Suppose self-driving cars would not be safe to use and make the correct decisions along the path from A → B. Nobody would use them.
But we can see that they are just getting more popular over time. And that is exactly where good AI Evaluation is so important. With a good evaluation process, you ensure that your AI product works correctly and that it provides what users need and expect. 1.3 Iterating Quickly == SuccessLike in software engineering, success with AI depends on how quickly you can test and improve ideas. You must have processes and tools for:
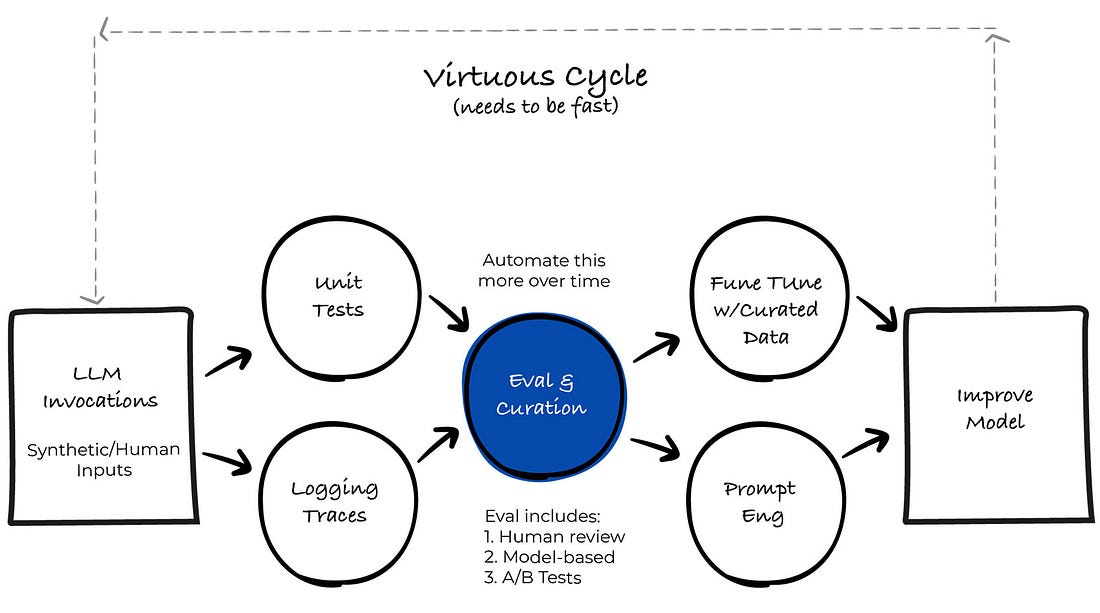
Doing all three activities well creates a virtuous cycle differentiating great from mediocre AI products (see the diagram below for a visualization of this cycle). If you streamline your evaluation process, all other activities become easy. This is very similar to how tests in software engineering pay massive dividends in the long term despite requiring up-front investment. To ground this article in a real-world situation, we’ll go over a case study in which we built a system for rapid improvement. We’ll primarily focus on evaluation, as that is the most critical component. 2. Case Study: Lucy, A Real Estate AI AssistantRechat is a SaaS application that allows real estate professionals to perform various tasks, such as managing contracts, searching for listings, building creative assets, managing appointments, and more. The thesis of Rechat is that you can do everything in one place rather than having to context switch between many different tools. Rechat’s AI assistant, Lucy, is a canonical AI product: a conversational interface that obviates the need to click, type, and navigate the software. During Lucy’s beginning stages, rapid progress was made with prompt engineering. However, as Lucy’s surface area expanded, the performance of the AI plateaued. Symptoms of this were:
2.1 Problem: How To Systematically Improve The AI?To break through this plateau, we created a systematic approach to improving Lucy centered on evaluation. Our approach is illustrated by the diagram below:
This diagram is a best-faith effort to illustrate the mental model for improving AI systems. In reality, the process is non-linear and can take on many different forms that may or may not look like this diagram. We’ll discuss about the various components of this system in the context of evaluation below. 2.2 The Types Of EvaluationRigorous and systematic evaluation is the most important part of the whole system. That is why “Eval and Curation” is highlighted in blue at the center of the diagram. You should spend most of your time making your evaluation more robust and streamlined. There are three levels of evaluation to consider:
This dictates the cadence and manner you execute them. For example, I often run Level 1 evals on every code change, Level 2 on a set cadence and Level 3 only after significant product changes.
It’s also helpful to conquer a good portion of your Level 1 tests before you move into model-based tests, as they require more work and time to execute. There isn’t a strict formula as to when to introduce each level of testing. You want to balance getting user feedback quickly, managing user perception, and the goals of your AI product. This isn’t too dissimilar from the balancing act you must do for products more generally. 2.3 Level 1: Unit Tests...Subscribe to Engineering Leadership to unlock the rest.Become a paying subscriber of Engineering Leadership to get access to this post and other subscriber-only content. A subscription gets you:
|